
Resources
Resources
GPU Servers in Malaysia
Fuel your AI projects with IP ServerOne’s bare metal GPU servers—dedicated, affordable, and purpose–built for AI/ML, HPC, and other compute-intensive workloads.
Powered by NVIDIA GPU technology, our bare metal GPU servers are engineered for AI, machine learning (ML), deep learning, and high-performance computing workloads. Designed for model training, fine-tuning, inference, and large-scale data processing, they deliver consistent, high-throughput performance with full hardware access in a dedicated single-tenant environment. Our GPU lineup includes RTX 3090, RTX 4090, RTX 5090, RTX 6000 Ada, and enterprise-grade accelerators such as the H200 NVL — enabling secure, scalable infrastructure for data-intensive AI applications. With no virtualization overhead, enhanced data control, and 24/7 local technical support, our GPU servers provide reliable, high-performance infrastructure for production-grade AI deployments.
The Challenges of AI: High Costs, Complex Infrastructure, and Data Risks

High Cost of GPUs
Training complex models, running deep learning, natural language processing (NLP), or scientific simulations all require GPUs—an expensive upfront investment that creates a major barrier.

Infrastructure Design and Maintenance
AI/ML workloads require specialized networking, storage, and compute resources, which can be challenging to configure optimally. Hardware failures and GPU degradation can disrupt operations.

Security & Data Sovereignty
Running AI models on shared cloud GPUs exposes sensitive data to potential breaches. Industries like healthcare, finance, and government must ensure compliance and mitigate these risks.
NovaGPU: On-Demand GPUs for Your AI Projects
Run training, fine-tuning, and inference with pay-as-you-go GPU compute. Get started with the RTX 5090 at MYR 3.05/hour, or choose RTX 3090 from MYR 1.82/hour and H200 NVL from MYR 19.09/hour.
Start today and scale effortlessly whenever you need.
Benefits of GPU Servers

Accelerate AI Deployment
Speed up AI and machine learning projects with GPUs from RTX 3090, RTX 4090, RTX 5090, RTX 6000 Ada to H200 NVL — delivering faster training, fine-tuning, and real-time inference for demanding AI applications.

Cost-Effective AI Solutions
Get premium GPU servers at competitive rates with flexible subscription models, ensuring predictable pricing and no hidden fees—without compromising quality or reliability.

Secure & Dedicated Infrastructure
Run AI workloads on bare metal GPU servers with dedicated resources, ensuring full control, uncompromised performance, and strict data sovereignty in a single-tenant environment.

Peace of Mind
Enjoy 24/7 support and hosting in a secure, high-availability Tier III data center, so you can focus on your core business while we handle your infrastructure.
Versatile Use Cases
Host AI applications with dedicated GPU power, delivering the performance needed for LLMs, generative AI, scientific simulations, and other compute-intensive workloads.

Simplified Deployment and Management
Let us handle the hardware setup, configuration, and ongoing maintenance, so you can focus on bringing your innovations to life.
Dream Big, Compute Bigger!
Unleash the full potential of your projects with high-performance GPU servers today.
Key Features of GPU Servers
Dream Big, Compute Bigger!
Unlock the full potential of your AI projects with powerful GPU servers at a fraction of the cost.
High-Performance NVIDIA GPUs
Leverage GPUs from RTX 3090, RTX 4090, RTX 5090, RTX 6000 Ada to H200 NVL for fast AI/ML training, fine-tuning, inference, and demanding workloads like simulations, rendering, and high-end graphics.
Custom GPU Servers for Any AI Workload
Customize your server with the GPU, AI models, memory, and storage you need for maximum performance—perfect for chatbots, AI agents, automation, and more—while ensuring full compliance and security.
Optimized for AI/ML & HPC Workloads
Designed for demanding AI/ML and high-performance computing (HPC) tasks, our GPU servers ensure high-speed training, precise inference, and reliable performance for complex models and custom applications.
Model Fine-Tuning
Fine-tune your pre-trained models with ease using our GPU servers, ensuring the accuracy and performance needed for your unique applications in a controlled, isolated environment.
24/7 Support Assistance
Benefit from around-the-clock support from our experienced engineers, ensuring your GPU servers run smoothly, with quick issue resolution to maintain optimal performance.
Enterprise-Grade Hosting
Rest easy knowing your applications are hosted in our Tier III data center, providing top-tier security, reliability, and high availability for mission-critical workloads.
GPUs Benchmark
GPU Compute Performance
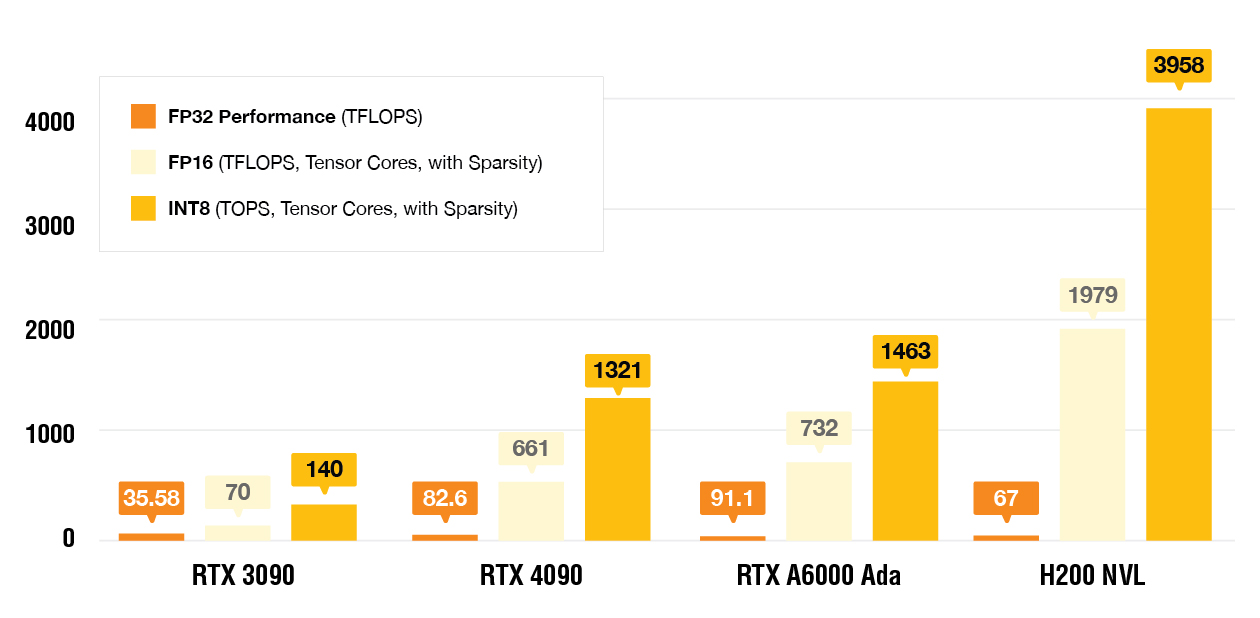
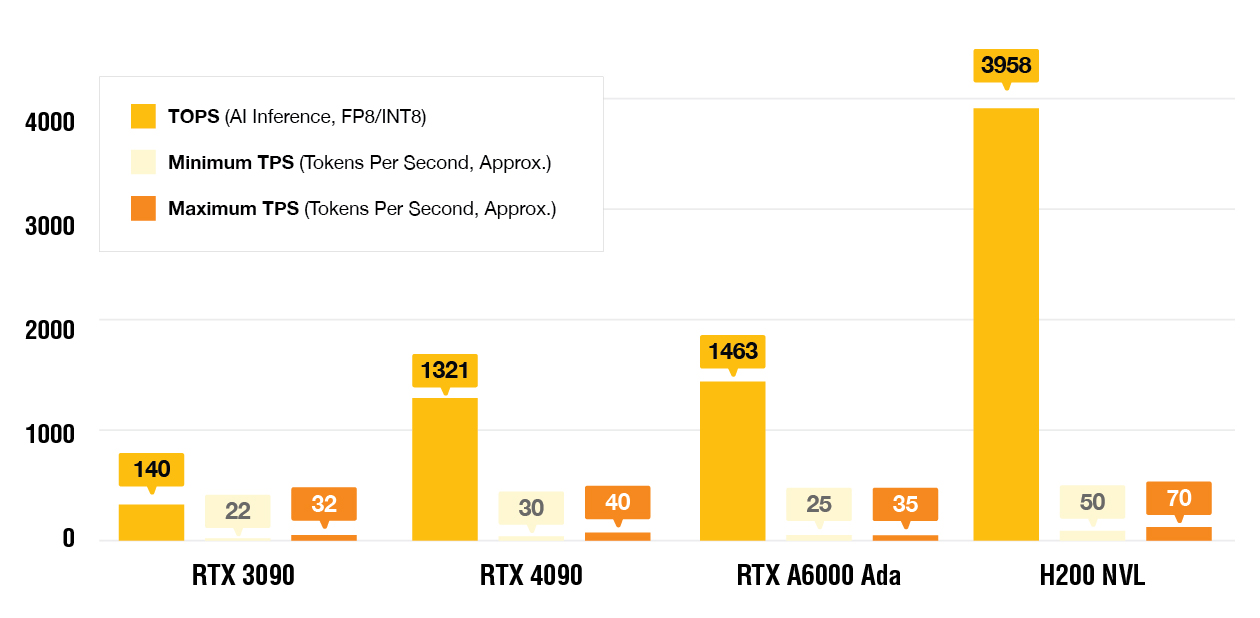
AI Processing Power: TOPS vs TPS
Notes:
- TOPS (Tera Operations Per Second) measures peak AI inference performance with Tensor Cores, but real-world results depend on workload and software optimization.
- TPS (Tokens Per Second) varies by model (e.g., LLaMA, GPT), batch size, and optimizations, making figures approximate based on benchmarks. For detailed benchmarks, visit NVIDIA’s official website.
Available GPU Options
We offer a range of NVIDIA GPUs options to cater to your specific AI needs:
NVIDIA GeForce RTX 3090
NVIDIA GeForce RTX 4090
NVIDIA GeForce RTX 5090
NVIDIA RTX 6000 Ada
NVIDIA H200 NVL Tensor Core
NVIDIA GeForce RTX 3090
The RTX 3090, based on NVIDIA’s Ampere architecture, is a consumer GPU with 24GB of GDDR6X VRAM and 328 Tensor Cores. It provides adequate performance for AI/ML workloads, content creation, and gaming, serving as a reasonable option for enthusiasts and solo developers working on moderately demanding tasks.
- Training: Delivers decent speeds, roughly 5–15% faster than its predecessor depending on model and workload, with 3rd-gen Tensor Cores offering basic deep learning support.
- Fine-Tuning: Shows modest gains, with improvements varying by model size and task complexity.
- Inference: Handles real-time inference for small to medium AI tasks, though its 24GB VRAM can limit larger projects.
NVIDIA GeForce RTX 4090
The RTX 4090, built on NVIDIA’s Ada Lovelace architecture, is a high-end consumer GPU with 24GB of GDDR6X VRAM and 512 Tensor Cores. It steps up compute performance for AI/ML workloads, gaming, and content creation, making it a solid choice for users needing more power and efficiency.
- Training: Up to 50–70% faster than its predecessor, depending on model and workload, with 4th-gen Tensor Cores enhancing deep learning tasks.
- Fine-Tuning: Delivers noticeable improvements, with performance varying by model complexity and task needs.
- Inference: Supports real-time inference across a range of AI applications, boosted by high bandwidth, though 24GB VRAM may cap larger models.
NVIDIA GeForce RTX 5090
The RTX 5090, built on NVIDIA’s new Blackwell architecture, is a next‑gen enthusiast GPU with 32 GB of GDDR7 VRAM, 21,760 CUDA cores, and 680 (5th‑gen) Tensor Cores. It delivers enormous compute performance gains for AI/ML workloads, content creation, and cutting‑edge graphics, making it ideal for users who need maximum power, memory bandwidth, and future‑proof GPU compute.
- Training: Significantly faster than previous‑gen GPUs. 5th‑gen Tensor Cores and 32 GB of VRAM with high bandwidth let you train larger models or batches with fewer memory bottlenecks.
- Fine-Tuning/Transfer Learning: More VRAM and upgraded Tensor Cores give extra headroom for fine-tuning complex models or larger datasets, reducing previous limitations.
- Inference: Real-time inference for larger models is easier with expanded VRAM, higher bandwidth, and improved Tensor Core throughput.
NVIDIA RTX 6000 Ada
The RTX 6000 Ada, a professional-grade GPU from NVIDIA’s Ada Lovelace lineup, boasts 48GB of GDDR6 VRAM and robust compute power. It’s built for tougher tasks like AI, complex simulations, and 3D rendering, offering greater precision and capacity for advanced AI/ML users.
- Training: Up to 2x faster than its predecessor, depending on model and workload, with 4th-gen Tensor Cores driving strong deep learning performance.
- Fine-Tuning: Provides clear performance gains, influenced by model size and task complexity.
- Inference: Excels at real-time inference for advanced AI applications, with extra VRAM supporting bigger projects.
NVIDIA H200 NVL Tensor Core
The H200 NVL, NVIDIA’s advanced Hopper-based datacenter GPU, boasts 141GB of HBM3e VRAM and 528 Tensor Cores. Engineered for next-generation AI/ML, high-performance computing (HPC), and enterprise workloads, it offers exceptional computational power and energy efficiency with its enhanced memory capacity and bandwidth.
- AI Training: Achieves up to 5x faster training than its predecessors for large language models, leveraging 4th-gen Tensor Cores and the Transformer Engine optimized for deep learning.
- Fine-tuning: Delivers substantial performance gains, scaling efficiently with model complexity and task demands, thanks to its 1.5x memory increase over the H100 NVL.
- Inference: Excels in real-time inference for large-scale AI applications, providing up to 1.7x faster performance than the H100 NVL, driven by its 4.8TB/s memory bandwidth and NVLink connectivity.
Note: Performance estimates are general guidelines and may vary depending on your AI model, dataset, software, and hardware configuration. For detailed benchmarks, refer to NVIDIA’s official website.
Find the Right GPU for Your AI Needs
Comparing RTX 3090, RTX 4090, RTX 5090, RTX 6000 Ada, and H200 NVL
Find the Right GPU for Your AI Projects
Choosing the right GPU for AI/ML can be tricky. Use our quick comparison to find the best fit—for reference only.
| Specification | RTX 3090 | RTX 4090 | RTX 5090 | RTX 6000 Ada | H200 NVL |
| Service Offering | Bare-metal and NovaGPU | Bare-metal and NovaGPU | Bare-metal and NovaGPU | Bare-metal | Bare-metal and NovaGPU |
| Architecture | Ampere | Ada Lovelace | Blackwell | Ada Lovelace | Hopper |
| CUDA Cores | 10,496 | 16,384 | 21,760 | 18,176 | Estimated over 20,000 |
| Tensor Cores | 328 (3rd Gen) | 512 (4th Gen) | 680 (5th Gen) | 568 (4th Gen) | 1,370 (5th Gen) |
| AI TOPS | 285 | 1,321 | 3,352 | 1,457 | 3,341 |
| GPU Memory (VRAM) | 24GB GDDR6X | 24GB GDDR6X or 48GB GDDR6X | 32GB GDDR7 | 48GB GDDR6 | 141GB HBM3e |
| Memory Bandwidth | 936 GB/s | 1,008 GB/s | 1,792 GB/s | 960 GB/s | 4,800 GB/s |
| Process Node | 8nm (Samsung) | 4nm (TSMC) | 5nm (TSMC) | 4nm (TSMC) | 4nm (TSMC) |
| AI Use Case | Small-scale AI training/inference (e.g., 7B LLMs) | Medium-scale AI training/inference (e.g., 13B–22B LLMs) | Large-scale AI training/inference (e.g., 30B–70B LLMs) | Large-scale AI training/inference (e.g., 44B LLMs) | Massive-scale AI training/inference (e.g., 100B+ LLMs) |
| Important Notes: |
|
GPU Plans and Pricing
SINGLE GPU Plans
Single GPU plans include:
- RAID: Software RAID 1
- Bandwidth: 300Mbit/s
- Power Supply: Single
| Single GPU Server | ||||||||
| GPU Model | GPU Cards | VRAM | Per GPU Performance | CPU | Processor | RAM | Hard Drive | Price / Month |
| RTX 3090 | 1 x NVIDIA GeForce RTX 3090 | 24GB | FP32 TFLOPS: 35.6 AI TOPS: 285 GPU Memory Bandwidth: 936.2GB/s | 16 Cores 3.0GHz | AMD EPYC™ 7313 | 64GB | 1 x 3.8TB NVME/SSD | MYR 1,499+ |
| RTX 4090 | 1 x NVIDIA GeForce RTX 4090 | 24GB | FP32 TFLOPS: 82.6 AI TOPS: 1,321 GPU Memory Bandwidth: 1,008GB/s | 16 Cores 3.0GHz | AMD EPYC™ 7313 | 64GB | 1 x 3.8TB NVME/SSD | MYR 2,099+ |
| RTX 5090 | 1 x NVIDIA GeForce RTX 5090 | 32GB | FP32 TFLOPS: 104.8 AI TOPS: 3,352 GPU Memory Bandwidth: 1,792GB/s | 16 Cores 3.0GHz | AMD EPYC™ 7313 | 64GB | 1 x 3.8TB NVME/SSD | Get Quote |
| H200 NVL | 1 x NVIDIA H200 NVL | 141GB | FP32 TFLOPS: 60 AI TOPS: 3,341 GPU Memory Bandwidth: 4,800GB/s | 16 Cores 3.0GHz | AMD EPYC™ 7313 | 64GB | 1 x 3.8TB NVME/SSD | Get Quote |
DUAL GPU Plans
DUAL GPU plans include:
- RAID: non-RAID
- Bandwidth: 300Mbit/s
- Power Supply: Single
| Single GPU Server | ||||||||
| GPU Model | GPU Cards | VRAM | Per GPU Performance | CPU | Processor | RAM | Hard Drive | Price / Month |
| RTX 4090 | 2 x NVIDIA GeForce RTX 4090 | 48GB (2 x 24GB) | FP32 TFLOPS: 82.6 AI TOPS: 1,321 GPU Memory Bandwidth: 1,008GB/s | 16 Cores 3.0GHz | AMD EPYC™ 7313 | 128GB | 2 x 7.6TB NVME/SSD | MYR 4,599+ |
| RTX 5090 | 2 x NVIDIA GeForce RTX 5090 | 64GB (2 x 32GB) | FP32 TFLOPS: 104.8 AI TOPS: 3,352 GPU Memory Bandwidth: 1,792GB/s | 16 Cores 3.0GHz | AMD EPYC™ 7313 | 128GB | 2 x 7.6TB NVME/SSD | Get Quote |
| RTX 6000 Ada | 2 x NVIDIA A6000 Ada | 96GB (2 x 48GB) | FP32 TFLOPS: 91.1 AI TOPS: 1,457 GPU Memory Bandwidth: 960GB/s | 16 Cores 3.0GHz | AMD EPYC™ 7313 | 128GB | 2 x 7.6TB NVME/SSD | MYR 7,950+ |
| H200 NVL | 2 x NVIDIA H200 NVL | 282GB (2 x 141GB) | FP32 TFLOPS: 60 AI TOPS: 3,341 GPU Memory Bandwidth: 4,800GB/s | 16 Cores 3.0GHz | AMD EPYC™ 7313 | 128GB | 2 x 7.6TB NVME/SSD | Get Quote |
QUAD GPU Plans
QUAD GPU plans include:
- RAID: non-RAID
- Bandwidth: 300Mbit/s
- Power Supply: Dual
| Single GPU Server | ||||||||
| GPU Model | GPU Cards | VRAM | Per GPU Performance | CPU | Processor | RAM | Hard Drive | Price / Month |
| RTX 4090 | 4 x NVIDIA GeForce RTX 4090 | 96GB (4 x 24GB) | FP32 TFLOPS: 82.6 AI TOPS: 1,321 GPU Memory Bandwidth: 1,008GB/s | 16 Cores 3.0GHz | AMD EPYC™ 9124 | 256GB | 2 x 7.6TB NVME/SSD | MYR 7,999+ |
| RTX 5090 | 4 x NVIDIA GeForce RTX 5090 | 128GB (4 x 32GB) | FP32 TFLOPS: 104.8 AI TOPS: 3,352 GPU Memory Bandwidth: 1,792GB/s | 16 Cores 3.0GHz | AMD EPYC™ 9124 | 256GB | 2 x 7.6TB NVME/SSD | Get Quote |
| RTX 6000 Ada | 4 x NVIDIA A6000 Ada | 192GB (4 x 48GB) | FP32 TFLOPS: 91.1 AI TOPS: 1,457 GPU Memory Bandwidth: 960GB/s | 16 Cores 3.0GHz | AMD EPYC™ 9124 | 256GB | 2 x 7.6TB NVME/SSD | MYR 14,999+ |
Notes:
• +: Subject to 8% SST. Prices are provided as a guide, may vary due to changes in foreign exchange rates.
Related Services
Enhance your GPU experience with IP ServerOne’s solutions, ensuring seamless performance and peace of mind for your AI journey.
NovaGPU
On-demand access to affordable and secure GPUaaS.
- Affordable, dedicated GPU on demand
- Accelerate your AI-driven projects and applications
- Fine-tune models, perform real-time inference, and run simulations on data-sovereign GPUs
Managed Private Cloud
Dedicated and Customized Cloud Environment.
- Heightened security by having full control over your server.
- Customized setup for every need.
- On-prem or legacy system to the cloud.
Colocation
A Safe Space for Your Servers and IT Equipment.
- Neutral-carrier. Tier III data center in CJ1 Malaysia.
- 24x7 NOC support assistance.
- Compliant with ISO27001, ISO27017, PCI-DSS, SOC 2 Type II.
Acorn Recovery as a Service
Restore Your IT Infrastructure within Minutes.
- Managed backup and disaster recovery solution.
- Simplified your ransomware recovery.
- Compliant with ISO27001, ISO27017, BNM RMiT, SOC 2 Type II.
Use Cases for GPU Servers
Common deployment scenarios for our GPU servers.
Accelerating Software Development & AI Training
Fine-Tuning Chatbot Models for Accuracy
Fast-Track Video Rendering & Content Creation
Accelerating Software Development & AI Training
Industries: Gaming, AI/ML, AR/VR, Technology
Challenge: Building complex applications like gaming engines or AI solutions demands significant computing power. Long training times for AI models and resource-heavy testing can delay project timelines.
Solution: GPU servers speed up software development and AI training by reducing testing times and enabling faster iterations. This helps teams deliver high-quality software and AI-driven solutions on schedule.
Fine-Tuning Chatbot Models for Accuracy
Industries: Customer Support, E-commerce, Financial Services, Healthcare
Challenge: Chatbots need to understand specific industries and contexts to deliver accurate responses, but fine-tuning with large, domain-specific datasets can be slow and computationally expensive.
Solution: GPU servers accelerate the fine-tuning of RAG chatbot models, enabling them to learn from large datasets quickly and improve their accuracy in real-time. This helps businesses provide faster, more precise customer support while ensuring data privacy.
Fast-Track Video Rendering & Content Creation
Industries: Media, Advertising, Architecture
Challenge: Tasks like rendering 4K/8K videos, 3D animations, or architectural models often take hours, delaying production.
Solution: GPU servers handle rendering-heavy workflows effortlessly, delivering faster results for video editing, special effects, and 3D modeling, ensuring creative projects stay on track.
Frequently Asked Questions
GPU servers are high-performance computing systems designed to accelerate processing tasks by using Graphics Processing Units (GPUs) rather than just Central Processing Units (CPUs). These servers are optimized for parallel computing tasks, such as AI/ML, data processing, scientific simulations, gaming, and more, making them ideal for handling demanding workloads.
GPUs are specialized hardware designed to handle multiple calculations simultaneously, which is why they excel at tasks that require parallel processing, such as AI/ML training, video rendering, and simulations. Unlike CPUs, which handle sequential tasks, GPUs can process large chunks of data at once, significantly speeding up tasks like training machine learning models or rendering high-resolution graphics.
GPUs (Graphics Processing Units) were originally designed for rendering graphics but are now essential for AI, data processing, and more. Unlike CPUs, GPUs can process multiple tasks simultaneously, making them ideal for demanding workloads. Common uses of GPUs include:
- AI & Machine Learning: Accelerates AI model training and inference for applications like chatbots, image recognition, and self-driving technology.
- Gaming & Graphics: Powers high-quality visuals in video games, movies, and 3D design for realistic rendering.
- Data Processing: Handles large datasets for research, simulations, and business analytics.
- Cryptocurrency Mining: Solves complex algorithms to validate blockchain transactions.
- Creative Work: Speeds up video editing, 3D modeling, and rendering for professionals.
- Everyday Performance: Enhances app responsiveness and display quality in laptops and mobile devices.
A bare metal GPU is a physical GPU installed in a dedicated server that you fully control. This setup provides direct access to the GPU’s full performance, ensuring low latency, maximum customization, and no resource sharing, making it ideal for high-performance tasks like AI/LLM training, rendering, and scientific simulations. You are responsible for maintenance, cooling, and power management.
A GPU as a Service (GPUaaS) is a virtualized GPU hosted in a provider’s data center and accessed remotely over the internet. It offers flexibility and scalability, letting you rent GPUs like the RTX 4090 or RTX 5090 for specific tasks without upfront hardware costs. While GPUaaS is convenient and cost-effective, it may involve shared resources, potential latency, and less control over hardware, which can affect performance for latency-sensitive workloads.
There are a few types of GPU server deployments, each suited to different needs:
- Bare-Metal GPU servers: Physical servers with dedicated GPUs for tasks like AI/ML training, data processing, and gaming. They provide the best performance for heavy workloads.
- Cloud-based GPU servers: On-demand GPU resources that you can scale as needed, without buying hardware. Ideal for businesses seeking flexible, cost-effective GPU solutions.
- Hybrid GPU servers: A mix of bare-metal and cloud-based resources. This setup gives you the flexibility of the cloud with the performance of physical servers, ideal for businesses that need both scalability and high power for tasks like AI/ML and big data.
Bare metal GPUs deliver dedicated, high-performance computing power without virtualization overhead, making them ideal for AI and intensive workloads. Here’s why they stand out:
- Maximum Performance: Full access to the GPU’s power without shared resources, ensuring faster computations and lower latency.
- Stability & Reliability: No virtualization means predictable performance, making them perfect for AI training, deep learning, and scientific simulations.
- Optimized for AI & ML: Handles complex models, large datasets, and intensive computations more efficiently than virtualized alternatives.
- Flexible & Scalable: Customizable to meet specific AI needs, making them a great choice for businesses with demanding workloads.
- Cost-Effective for Heavy Workloads: Eliminates resource-sharing inefficiencies, providing better value for sustained, high-intensity computing tasks.
Choosing the right GPU server depends on the type of workload you need to handle. Here are some factors to consider:
- Define your workload: Identify the specific applications you’ll be running (e.g., AI training, scientific simulations, video rendering).
- Determine your performance requirements: Consider factors like throughput, latency, and the volume of data you need to process.
- Assess your budget: GPU servers can range in price significantly. Determine your budget constraints to narrow down your options.
- Evaluate your cooling and power requirements: Ensure your chosen server has adequate cooling and power infrastructure to support the GPUs.
- Consider future scalability: Choose a server that can be easily upgraded or expanded to accommodate future growth.
Yes! GPUs (Graphics Processing Units) are essential for AI and Large Language Model (LLM) workloads because of their parallel processing capabilities, which significantly accelerate tasks like model training, inference, and data processing compared to CPUs.
How to choose the right GPU for AI:
- AI Workload Type: For training large or complex models, high-end GPUs like the H200 NVL or RTX 5090 deliver maximum performance, while mid-range GPUs such as the RTX 3090 or RTX 4090 are cost-effective and powerful enough for inference or smaller AI tasks.
- Memory (VRAM): Large AI models and datasets require more GPU memory. Choose GPUs with higher VRAM, like the RTX 5090, for deep learning and large-scale model training.
- Compute Power: GPUs with higher TFLOPS and more CUDA cores process tasks faster. Keep in mind that infrastructure, network performance, and data pipelines also affect overall speed.
- Budget & Flexibility: GPU as a Service (GPUaaS) platforms like NovaGPU allow pay-as-you-go access to high-performance GPUs, helping you balance power, cost, and flexibility without upfront hardware investments.
The best GPU for AI depends on your project size, goals, and budget. At IP ServerOne, we offer a range of bare metal GPUs and GPU-as-a-Service (NovaGPU) to suit different AI/ML workloads. Here’s our recommendation:
- RTX 3090: A budget-friendly option for smaller AI projects like image recognition and basic models. Ideal for beginners or small teams starting out in AI.
- RTX 4090: A powerful and efficient choice for handling larger models and datasets. Great for solo developers or growing projects needing strong compute performance.
- RTX 5090: A next-generation GPU with bigger VRAM and enhanced Tensor cores, ideal for training larger models, fine-tuning complex datasets, and high-performance AI workloads.
- RTX 6000 Ada: A professional-grade GPU with extra memory and stability, perfect for businesses and professionals running advanced AI applications or enterprise workloads.
- H200 NVL: The top-tier choice for massive AI projects, research, and enterprise-scale workloads, built for high-end AI development and large-scale model training.
IP ServerOne offers two types of GPU solutions for AI workloads: bare metal GPU servers and a fully managed GPU as a Service (GPUaaS) solution called NovaGPU.
Here’s a quick comparison to help you decide which fits your needs:
| Feature | Bare Metal GPU | NovaGPU (GPUaaS) |
| Nature | Dedicated physical GPU server | Fully managed, cloud GPU service with dedicated GPU card |
| Pricing | Subscription-based | Hourly or subscription-based |
| Management | We handle the initial setup—you can choose to manage the server yourself or opt for our managed service, where we take care of maintenance, upgrades, and server management for you | Fully managed infrastructure by IP ServerOne – you only manage your applications and data |
| Security & Backup | Customizable security with optional backup and disaster recovery add-ons | Built-in HA setup, end-to-end encryption, and automated snapshot backups (hourly, daily, weekly) at no extra cost |
| Suggested Use Cases | Suitable for teams with in-house technical expertise managing long-term, resource-heavy projects | Ideal for agile development, R&D, model training, and projects with flexible timelines or scaling needs |
Depending on your use case, budget, and technical preferences, you can choose between bare metal GPU and NovaGPU to best support your AI initiatives.